


This is the third post in a series applying a systematic Agent Readiness Assessment to DoveRunner’s developer documentation, evaluating whether AI coding agents can generate correct integration code, or silently produce broken implementations. Here’s post one and post two.
In April 2026, Cloudflare launched “ ” a tool that evaluates how well a Is Your Site Agent-Ready?
website can be discovered and consumed by AI agents. We scanned , DoveRunner Docs
DoveRunner’s developer documentation site covering both its Content Security and Mobile App Security product lines.
Because DoveRunner Docs is a developer documentation site rather than an API server or transactional web app, we ran the scan in its content-site profile — the mode that evaluates the checks relevant to content sites and sets aside the API/Auth/MCP and Commerce categories, which are designed for API servers and transactional applications rather than documentation sites.
Result: 43/100. Level 1: Basic Web Presence.
This post breaks down the scan results by category, explains what that score actually means, and identifies what neither scan tool measures.
What “Is Your Site Agent Ready?” Measures
The scanning site runs 19 checks across five categories. A content site is scored against the three that apply to it — Discoverability, Content, and Bot Access Control — for seven enabled checks in total.
Discoverability:
Can an agent find the site and locate entry points? Checks: robots.txt, sitemap, Link headers (RFC 8288), DNS-AID (an agent-specific DNS record standard). Content: Can an agent consume content without parsing HTML? Check: Markdown content negotiation ( Accept: text/markdown response).
Bot Access Control:
Does the site declare its intent toward AI bots? Checks: Per-crawler robots.txt rules, Content Signals (AI training/input declarations), Web Bot Auth (bot request signature verification).
API, Auth, MCP & Skill Discovery:
Can an agent autonomously identify the API structure and authentication flows? Checks: API Catalog (RFC 9727), OAuth/OIDC Discovery, MCP Server Card, Agent Skills Index, WebMCP.
Commerce:
Can an agent handle payments using micropayment standards (x402, MPP, etc.)? Not applicable to a developer documentation site.
In short: the tool measures the technical infrastructure of a site’s agent readiness. It does not examine content quality.
43/100: The Detail
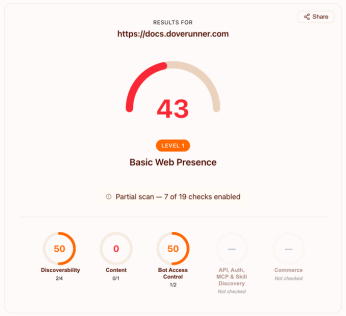
The content-site profile enables seven of the tool’s 19 checks — the three categories below — and sets aside the API, Auth, MCP & Skill Discovery and Commerce categories, whose checks, including OAuth Discovery, MCP Server Card, micropayment standards, and the like, describe API servers and transactional applications, not content sites. The score reflects those seven applicable checks.
Discoverability: 2 of 4 Passing, Category Score 50
| Check | Result | Notes |
| robots.txt | ✅ Pass | User-agent: * / Allow: / / Sitemap: …/sitemap index.xml |
| Sitemap | ✅ Pass | sitemap-index.xml valid |
| Link response headers (RFC 8288) | ❌ Fail | No Link header in homepage response |
| DNS-AID | ❌ Fail | _index._agents , _a2a._agents , _mcp._agents subdomains all NXDOMAIN |
DNS-AID enables agents to discover MCP servers and A2A (agent-to-agent) endpoints at the DNS level. It requires DNSSEC (DNS Security Extensions) and is still in early adoption. DNS-AID is in early adoption and not an immediate remediation priority — but it maps to Stage 3 infrastructure when DoveRunner builds out its MCP server.
Content — 0 of 1 Passing, 0 Points
| Check | Result | Notes |
| Markdown Negotiation | ❌ Fail | Accept: text/markdown request returns text/html (799ms) |
DoveRunner Docs runs on Astro + Starlight. The source content is written entirely in Markdown.
HTTP responses are always HTML. An agent sending Accept: text/markdown receives HTML. To consume Markdown directly, the agent must parse HTML or separately retrieve source files. This is the only check in the category, hence the 0.
Bot Access Control — 1 of 2 Passing (Conditional), Category Score 50
| Check | Result | Notes |
| AI bot rules in robots.txt | ✅ Conditional pass | Only wildcard Allow: / . No explicit rules for GPTBot, Claude-Web, or 13 other AI crawlers |
| Content Signals | ❌ Fail | No Content-Signal directive in robots.txt |
| Web Bot Auth | Skipped | Not for content site |
The AI bot pass is conditional. User-agent: * / Allow: / permits all crawlers, but says nothing about AI crawling specifically. Content Signals, the standard for declaring AI training, search indexing, and prompt input permissions directly in robots.txt, are absent. This is a single line addition.
The category’s third check, Web Bot Auth (verifying bot request signatures via a /.well known/http-message-signatures-directory ), is skipped in the content-site profile: DoveRunner Docs requires no authentication to read, so there is nothing for an agent to sign in to. That leaves two scored checks here, not three.
Not Scored: API, Auth, MCP and Skill Discovery, and Commerce
The content-site profile leaves two categories unscored.
API, Auth, MCP and Skill Discovery: covers API Catalog (RFC 9727), OAuth/OIDC Discovery, OAuth Protected Resource Metadata, Auth.md agent registration, MCP Server Card, Agent Skills Index, and WebMCP. This category evaluates whether an agent can autonomously identify a site’s API structure and authentication flows.
Commerce: covers micropayment standards like x402 and MPP, evaluating agent-driven payments. Neither category describes a documentation site, so the tool excludes them from the score.
They are not irrelevant to DoveRunner, though. They map directly onto the future MCP server: when it is built, publishing an MCP Server Card is how agent orchestrators will discover and connect to it, and an API Catalog is how agents will find what APIs exist. Those are Stage 3 concerns, which are out of scope for measuring this documentation site today but on the roadmap.
What This Score Means
43/100 still lands at Level 1, but the score doesn’t mean agents cannot use DoveRunner Docs . Claude and Codex parse HTML and extract content from a URL.
The infrastructure for agents to consume this site optimally is not in place. Without Markdown content negotiation, agents work through layout noise. Without an API Catalog, agents cannot autonomously discover what APIs exist. Without an MCP Server Card, agent orchestrators cannot declaratively identify what a future MCP server offers.
Mapped to the three-stage maturity model introduced in Part 2:
Stage 1 — Discoverability:
Partial robots.txt and sitemap pass. Link headers and llms.txt are absent. An llms.txt file is the highest-leverage immediate fix: adding a static file to the public/ directory resolves this check and clears all three Fern Agent Score content-discoverability failures simultaneously.
Stage 2 — Governance:
Not achieved Markdown content negotiation, Content-Signal, and per-crawler AI rules are all absent. Content-Signal and crawler rules require only robots.txt edits. Markdown delivery requires Astro/Starlight configuration work, but once done, agents consume structured Markdown directly without HTML parsing noise.
Stage 3 — Controlled Interaction:
Not started API Catalog, MCP Server Card, and OAuth Discovery are all absent. These sit in the categories the content-site scan leaves unscored, but they remain part of the broader maturity picture: medium-to-long-term architecture work that should be developed alongside the MCP server.
A Second Scan: A Complementary Lens
Twelve days later, we ran against the same site.
Fern’s Agent Score
Result: 0/100. Grade F. All five of the most important inspection items in the scan tool failed. These two scans measure different layers.
| Tool | Date | Score | Core Question |
| Is Your Site Agent-Ready? | 2026-05-29 | 43/100 | Can agents find the site and access its contents well? |
| Fern Agent Score | 2026-06-10 | 0/100 | Can agents read this content in a machine-friendly format? |
Is Your Site Agent-Ready? examines the “entry and navigation” path: bot access permissions, API catalog, MCP server cards, OAuth Discovery. Fern Agent Score checks two things: whether an llms.txt file exists (the standard entry point agents use to discover what pages a site contains) and whether the site can serve content as Markdown rather than HTML.
One failure overlaps between the two scans: Markdown content negotiation. The Content category failure in Is Your Site Agent-Ready? and the markdown-availability failures in Fern Agent Score point to the same root cause.
The remainder are distinct. Is Your Site Agent-Ready? caught bot access governance, API catalog, and MCP server cards. Fern caught llms.txt — a check Is Your Site Agent Ready? does not run at all.
Read the 0/100 the same way as 43/100: not “agents cannot read this documentation,” but “the standardized infrastructure for agents to consume this site without layout noise, autonomously, at scale, is not in place.” Together, the two scores map the full shape of that infrastructure gap.
What’s Next
The infrastructure checklist from these two scans is clear and actionable. But enabling agents to generate correct integration code requires evaluating the content layer separately.
The next post covers that work: a direct analysis of DoveRunner documentation using Claude to produce 23 end-to-end integration scenarios, and the agent failure points each scenario surfaced. The findings come from following actual integration journeys through the documentation — not from scanning tools.
Each post in this series moves closer to that answer: defining and closing the gaps between DoveRunner’s developer documentation and what AI coding agents need to generate correct integration code.

